Sam Altman 亲自下场:Codex 和 Claude Code 别吵了,"谁更强"的投票毫无意义
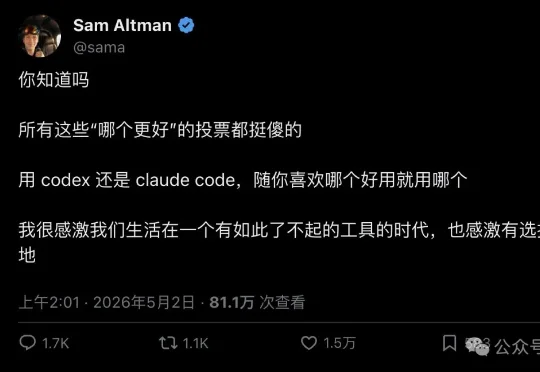
Sam Altman 亲自下场:Codex 和 Claude Code 别吵了,"谁更强"的投票毫无意义OpenAI CEO 一条推文拿下 80 万浏览、1.5 万点赞,开发者圈最火的"二选一"争论,被当事人自己按下了暂停键。5 月 2 日,Sam Altman 在 X 上发了一条看似随意、实则信息量极大的帖子:
来自主题: AI资讯
8320 点击 2026-05-04 13:21